Nothing makes me happier than pointing out when someone is wrong.
I admit, that’s a pretty sad life. And for some unfathomable reason that doesn’t endear me to the person who uttered the incorrect statement – which it really should as I’m correcting some mistaken belief of theirs, assisting them on the path to truth.
Perhaps, as Jonathan Haidt teaches us, my endeavour is a hopeless one as approaching truth is forever clouded by confirmation bias. Polarization runs rampant and scientific disciplines are scarred by replication crises and publication bias.
I don’t take issue with any of those points: reduce my ambitions to “a little less wrong” and what follows still holds.
A few days after the Riksbank had upped its interest rate to 0% last month, Daniel Lacalle, a Spanish economist, author and fund manager – and whose musings are usually quite insightful – decided to vent his (questionable) objections to central banks and negative interest rates (NIRP) in a very strange way:
- Deliver a bunch of vague one-liners about monetary policy and unsustainable capital markets.
- Make shit up about Sweden and Swedish capital markets.
Obviously, I don’t mind too much the rhetoric of those who vehemently oppose central banks, but I do mind people pulling numbers out of their behinds and just inventing things about the world that clearly are not true.
So let’s do some fact-checking.
It’s apparently really bad for governments to have public debt – and negative interest rates allegedly work like crack-cocaine for politicians in their endless desire for more and more and more underfunded expenditures. Spend away, minister!
Except that many (non-crisis) countries such as Sweden aren’t borrowing. In fact, Sweden’s debt-to-GDP ratio is at its lowest point since 2012 and has been dropping like a stone since about the time that the Riksbank first lowered its policy rate to below 0%. In fact, as the Riksbank sits on over 35% of the outstanding government debt, there’s been quite a scramble among commercial banks to meet their capital requirements; there aren’t enough bonds to go around. The big macro debate in Sweden right now is over how much more the government ought to spend given that the debt is so small.
My favorite part is when Lacalle starts inventing numbers to support his case. Strangely enough, he’s arguing that NIRP fuels an unsustainable boom such that increasing share prices and property prices (things that most of us individually tend to think are good or at least harmless) are, in Lacalle’s mind, actually evidence of how bad life is.
Ye, I too hate it when my retirement fund or house go up in value.
- Sweden’s “Real estate price index has increased 50 percent (from 160 points to 240).”
The official statistics agency, Statistics Sweden, reports a +17 increase in broad real estate indices since early 2015, but they only include data until late-2018. The index is also on a completely different level, suggesting that Lacalle used some other source.
Using numbers from Ekonomifakta we find house price increases of 9% and 19% across various regions from Q1 2015 (when the Riksbank NIRP policy began) to Q3 2019. Again, wrong index numbers so couldn’t have been Lacalle’s source.
But maybe house prices have increased some in the last few months such that Lacalle’s 50% number is correct? No, they’ve been flat, reports the realtor industry organization Svensk Mäklarstatistik.
Searching high and low for a Swedish house price index that conforms to Lacalle’s peculiar range (160 to 240), I finally found a promising one at Trading Economics:
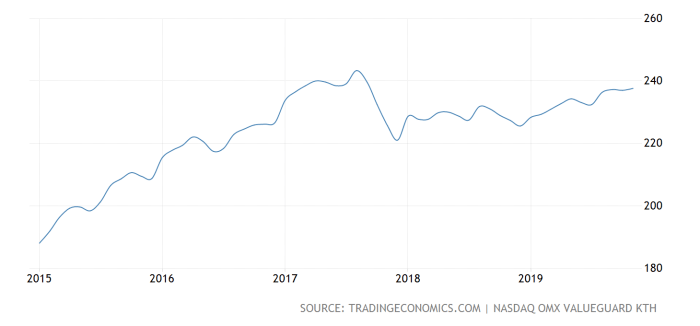
Interestingly enough, Lacalle seems to have misread the chart; the index value for Feb 2015 is around 190 – not 160 – producing a much more reasonable +26% increase over the last five years. Even that, as we’ve seen with the more reputable sources above, might be tad exaggerated.
2. Sweden’s stock market is up “more than 20%”
Next up: the stock market – always a grateful subject for unsubstantiated rants.
“more than 20%” is cheating as technically anything above “20%” would work. Curiously enough, no index for the Swedish stock market shows those numbers between Feb 18, 2015, and today:
- OMXS30, a commonly quoted index that does not include dividends, is up 8% since then.
- Using indices that do account for (reinvested) dividends, OMXSPI shows 27.5% gain since NIRP was introduced;
- OMXS30GI shows a 30.5% gain;
- and OMXSCAPGI reports a 52% return.
Then again, if gradually increasing stock markets are a bad thing, then why didn’t Lacalle go with the highest, most inflated number he could find?
3. “Average residential index” is apparently up 27%
Not a statistics I’m familiar with, but I refer the reader to (1) above for sources on property prices.
4. “nonreplicable assets have risen between 30 and 70 percent”
First: that’s quite a range, Sir.
Second: ye, I’ve never heard that term before (let alone something to measure it) – and neither, it seems, has Google. I suspect Lacalle invented some more numbers to complement his already fake-y statistics.
Tl;dr – don’t just make shit up, kids. Do look into your claims before you mindless utter them. You may be entitled to your own opinion (actually not really), but you can’t just believe whatever you want, making shit up along the way.