As COVID-19 continues to spread, fears and extraordinary predictions have also gone viral. While facing a new infectious threat, the unknowns of how new traits of our societies worldwide or of this novel coronavirus impact its spread. Though no two pandemics are equivalent, I thought it best to face this new threat armed with knowledge from past infectious episodes. The best inoculation against a plague of panic is to use evidence gained through billions of deaths, thousands of years, and a few vital breakthroughs to prepare our knowledge of today’s biological crises, social prognosis, and choices.
Below, I address three key questions: First, what precedents do we have for infections with catastrophic potential across societies? Second, what are the greatest killers and how do pandemics compare? Lastly, what are our greatest accomplishments in fighting infectious diseases?
As foundation for understanding how threats like COVID-19 come about and how their hosts fight back, I recommend reading The Red Queen concerning the evolutionary impact and mechanisms of host-disease competition and listening to Sam Harris’ “The Plague Years” podcast with Matt McCarthy from August 2019, which predated COVID-19 but had a strangely prophetic discussion of in-hospital strategies to mitigate drug resistance and their direct relation to evolutionary competition.
Infectious diseases plagued humanity throughout prehistory and history, with a dramatic decrease in the number of infectious disease deaths coming in the past 200 years. In 1900, the leading killers of people were (1) Influenza, (2) Tuberculosis, and (3) Intestinal diseases, whereas now we die from (1) Heart disease, (2) Cancer, and (3) Stroke, all chronic conditions. This graph shows not that humans have vanquished infectious disease as a threat, but that in the never-ending war of evolutionary one-upmanship, we have won battles consistently since 1920 forward. When paired with Jonathan Haidt’s Most Important Graph in the World, this vindicates humanity’s methods of scientific and economic progress toward human flourishing.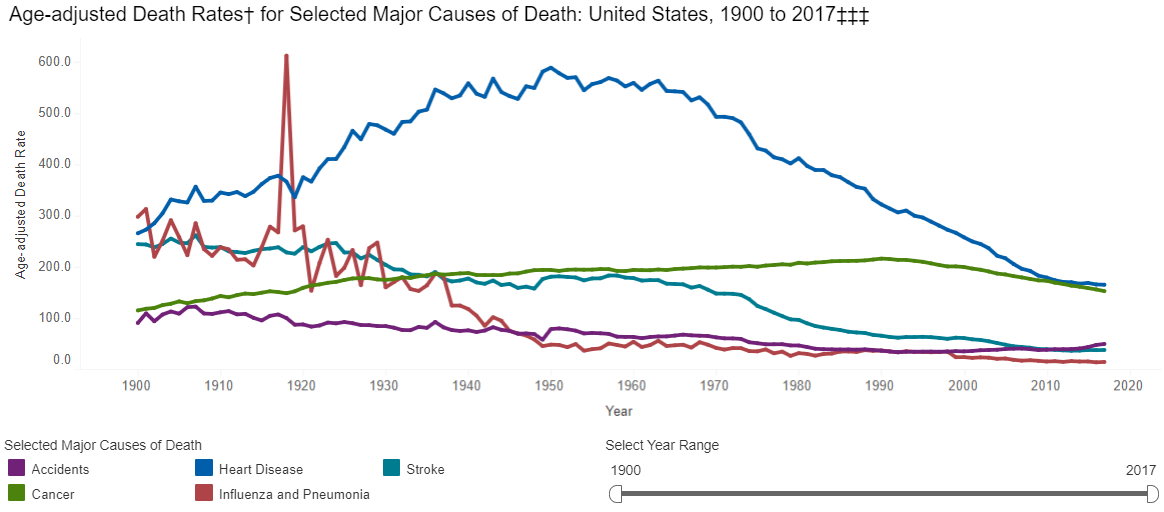
However, if the CDC had earlier data, it would show a huge range of diseases that dwarf wars and famines and dictators as causes of death in the premodern world. If we look to the history of plagues, we are really looking at the history of humanity’s greatest killers.
The sources on the history of pandemics are astonishingly sparse/non-comprehensive. I created the following graphs only by combining evidence and estimates from the WHO, CDC, Wikipedia, Our World in Data, VisualCapitalist, and others (lowest estimates shown where ranges were presented) for both major historic pandemics and for ongoing communicable disease threats. This is not a complete dataset, and I will continue to add to it, but it shows representative death counts from across major infectious disease episodes, as well as the death rate per year based on world population estimates. See the end of this post for the full underlying data. First, the top 12 “plagues” in history:
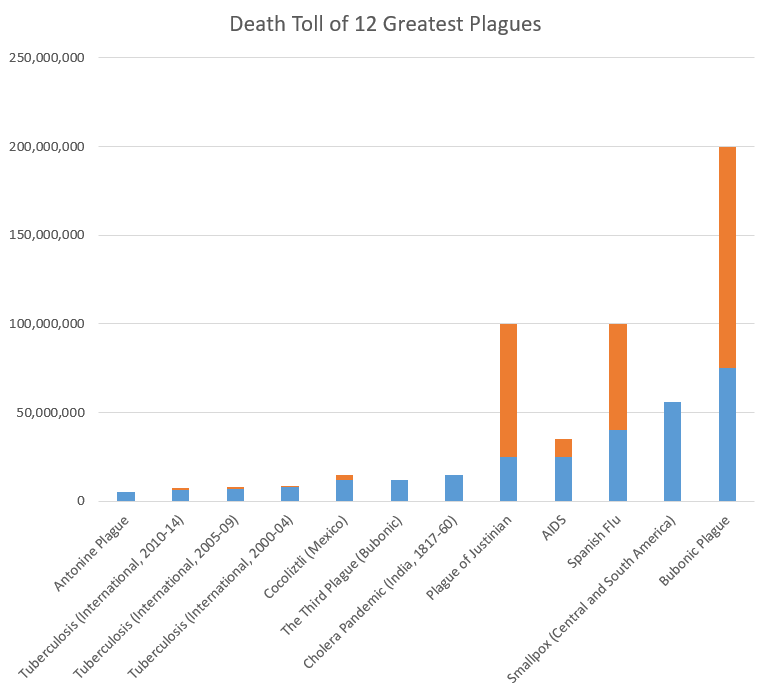
Note: blue=min, orange=max across the sources I examined. For ongoing diseases with year-by-year WHO evidence, like tuberculosis, measles, and cholera, I grouped mortality in 5-year spans (except AIDS, which does not have good estimates from the 1980s-90s, so I reported based on total estimated deaths).
Now, let’s look at the plagues that were lowest on my list (number 55-66). Again, my list was not comprehensive, but this should provide context for COVID-19:
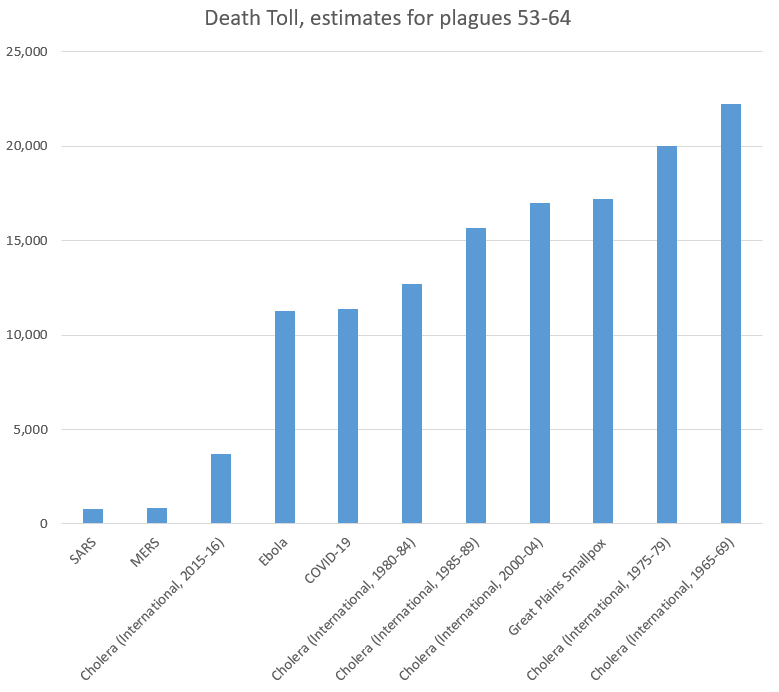
As we can see, the 11,400 people who have died from COVID-19 recently passed Ebola to take the 61st (out of 66) place on our list of plagues. Note again that several ongoing diseases were recorded in 5-year increments, and COVID-19 still comes in under the death rates for cholera. Even more notably, it has 0.015% as many victims as the plague in the 14th Century,
- In Context of Current Infectious Diseases:
For recent/ongoing diseases, it is easier to compare year-by-year data. Adding UNAIDS to our sources, we found the following rates of death across some of the leading infectious causes of death. Again, this is not comprehensive, but helps put COVID-19 (the small red dot, so far in the first 3 months of 2020) in context:
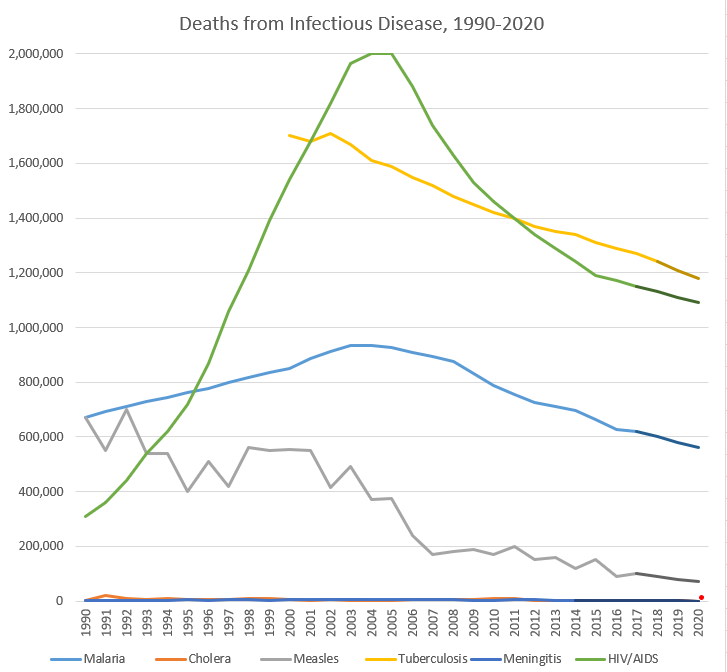
Note: darker segments of lines are my own estimates; full data at bottom of the post. I did not include influenza due to the lack of good sources on a year-by-year basis, but a Lancet article found that 291,000-645,000 deaths from influenza in a year is predictable based on data from 1999-2015.
None of this is to say that COVID-19 is not a major threat to human health globally–it is, and precautions could save lives. However, it should show us that there are major threats to human health globally all the time, that we must continue to fight. These trendlines tend to be going the right direction, but our war for survival has many foes, and will have more emerge in the future, and we should expend our resources in fighting them rationally based on the benefits to human health, not panic or headlines.
As we think about the way to address COVID-19, we should keep in mind that this fight against infectious disease builds upon work so amazing that most internet junkies approach new infectious diseases with fear of the unknown, rather than tired acceptance that most humans succumb to them. That is a recent innovation in the human experience, and the strategies used to fight other diseases can inform our work now to reduce human suffering.
While influenzas may be impossible to eradicate (in part due to an evolved strategy of constantly changing antigens), I wanted to direct everyone to an ever-growing monument to human achievement, the Eradication List. While humans have eradicated only a few infectious diseases, the amazing thing is that we can discuss which diseases may in fact disappear as threats through the work of scientists.
On that happy note, I leave you here. More History of Plagues to come, in Volume 2: Vectors, Vaccines, and Virulence!
| Disease |
Start Year |
End Year |
Death Toll (low) |
Death Toll (high) |
Deaths per 100,000 people per year (global) |
| Antonine Plague |
165 |
180 |
5,000,000 |
5,000,000 |
164.5 |
| Plague of Justinian |
541 |
542 |
25,000,000 |
100,000,000 |
6,250.0 |
| Japanese Smallpox Epidemic |
735 |
737 |
1,000,000 |
1,000,000 |
158.7 |
| Bubonic Plague |
1347 |
1351 |
75,000,000 |
200,000,000 |
4,166.7 |
| Smallpox (Central and South America) |
1520 |
1591 |
56,000,000 |
56,000,000 |
172.8 |
| Cocoliztli (Mexico) |
1545 |
1545 |
12,000,000 |
15,000,000 |
2,666.7 |
| Cocoliztli resurgence (Mexico) |
1576 |
1576 |
2,000,000 |
2,000,000 |
444.4 |
| 17th Century Plagues |
1600 |
1699 |
3,000,000 |
3,000,000 |
6.0 |
| 18th Century Plagues |
1700 |
1799 |
600,000 |
600,000 |
1.0 |
| New World Measles |
1700 |
1799 |
2,000,000 |
2,000,000 |
3.3 |
| Smallpox (North America) |
1763 |
1782 |
400,000 |
500,000 |
2.6 |
| Cholera Pandemic (India, 1817-60) |
1817 |
1860 |
15,000,000 |
15,000,000 |
34.1 |
| Cholera Pandemic (International, 1824-37) |
1824 |
1837 |
305,000 |
305,000 |
2.2 |
| Great Plains Smallpox |
1837 |
1837 |
17,200 |
17,200 |
1.7 |
| Cholera Pandemic (International, 1846-60) |
1846 |
1860 |
1,488,000 |
1,488,000 |
8.3 |
| Hawaiian Plagues |
1848 |
1849 |
40,000 |
40,000 |
1.7 |
| Yellow Fever |
1850 |
1899 |
100,000 |
150,000 |
0.2 |
| The Third Plague (Bubonic) |
1855 |
1855 |
12,000,000 |
12,000,000 |
1,000.0 |
| Cholera Pandemic (International, 1863-75) |
1863 |
1875 |
170,000 |
170,000 |
1.1 |
| Indian Smallpox |
1868 |
1907 |
4,700,000 |
4,700,000 |
9.8 |
| Franco-Prussian Smallpox |
1870 |
1875 |
500,000 |
500,000 |
6.9 |
| Cholera Pandemic (International, 1881-96) |
1881 |
1896 |
846,000 |
846,000 |
4.4 |
| Russian Flu |
1889 |
1890 |
1,000,000 |
1,000,000 |
41.7 |
| Cholera Pandemic (India and Russia) |
1899 |
1923 |
1,300,000 |
1,300,000 |
3.3 |
| Cholera Pandemic (Philippenes) |
1902 |
1904 |
200,000 |
200,000 |
4.2 |
| Spanish Flu |
1918 |
1919 |
40,000,000 |
100,000,000 |
1,250.0 |
| Cholera (International, 1950-54) |
1950 |
1954 |
316,201 |
316,201 |
2.4 |
| Cholera (International, 1955-59) |
1955 |
1959 |
186,055 |
186,055 |
1.3 |
| Asian Flu |
1957 |
1958 |
1,100,000 |
1,100,000 |
19.1 |
| Cholera (International, 1960-64) |
1960 |
1964 |
110,449 |
110,449 |
0.7 |
| Cholera (International, 1965-69) |
1965 |
1969 |
22,244 |
22,244 |
0.1 |
| Hong Kong Flu |
1968 |
1970 |
1,000,000 |
1,000,000 |
9.4 |
| Cholera (International, 1970-75) |
1970 |
1974 |
62,053 |
62,053 |
0.3 |
| Cholera (International, 1975-79) |
1975 |
1979 |
20,038 |
20,038 |
0.1 |
| Cholera (International, 1980-84) |
1980 |
1984 |
12,714 |
12,714 |
0.1 |
| AIDS |
1981 |
2020 |
25,000,000 |
35,000,000 |
13.8 |
| Measles (International, 1985) |
1985 |
1989 |
4,800,000 |
4,800,000 |
19.7 |
| Cholera (International, 1985-89) |
1985 |
1989 |
15,655 |
15,655 |
0.1 |
| Measles (International, 1990-94) |
1990 |
1994 |
2,900,000 |
2,900,000 |
10.9 |
| Cholera (International, 1990-94) |
1990 |
1994 |
47,829 |
47,829 |
0.2 |
| Malaria (International, 1990-94) |
1990 |
1994 |
3,549,921 |
3,549,921 |
13.3 |
| Measles (International, 1995-99) |
1995 |
1999 |
2,400,000 |
2,400,000 |
8.4 |
| Cholera (International, 1995-99) |
1995 |
1999 |
37,887 |
37,887 |
0.1 |
| Malaria (International, 1995-99) |
1995 |
1999 |
3,987,145 |
3,987,145 |
13.9 |
| Measles (International, 2000-04) |
2000 |
2004 |
2,300,000 |
2,300,000 |
7.5 |
| Malaria (International, 2000-04) |
2000 |
2004 |
4,516,664 |
4,516,664 |
14.7 |
| Tuberculosis (International, 2000-04) |
2000 |
2004 |
7,890,000 |
8,890,000 |
25.7 |
| Cholera (International, 2000-04) |
2000 |
2004 |
16,969 |
16,969 |
0.1 |
| SARS |
2002 |
2003 |
770 |
770 |
0.0 |
| Measles (International, 2005-09) |
2005 |
2009 |
1,300,000 |
1,300,000 |
4.0 |
| Malaria (International, 2005-09) |
2005 |
2009 |
4,438,106 |
4,438,106 |
13.6 |
| Tuberculosis (International, 2005-09) |
2005 |
2009 |
7,210,000 |
8,010,000 |
22.0 |
| Cholera (International, 2005-09) |
2005 |
2009 |
22,694 |
22,694 |
0.1 |
| Swine Flu |
2009 |
2010 |
200,000 |
500,000 |
1.5 |
| Measles (International, 2010-14) |
2010 |
2014 |
700,000 |
700,000 |
2.0 |
| Malaria (International, 2010-14) |
2010 |
2014 |
3,674,781 |
3,674,781 |
10.6 |
| Tuberculosis (International, 2010-14) |
2010 |
2014 |
6,480,000 |
7,250,000 |
18.6 |
| Cholera (International, 2010-14) |
2010 |
2014 |
22,691 |
22,691 |
0.1 |
| MERS |
2012 |
2020 |
850 |
850 |
0.0 |
| Ebola |
2014 |
2016 |
11,300 |
11,300 |
0.1 |
| Malaria (International, 2015-17) |
2015 |
2017 |
1,907,872 |
1,907,872 |
8.6 |
| Tuberculosis (International, 2015-18) |
2015 |
2018 |
4,800,000 |
5,440,000 |
16.3 |
| Cholera (International, 2015-16) |
2015 |
2016 |
3,724 |
3,724 |
0.0 |
| Measles (International, 2019) |
2019 |
2019 |
140,000 |
140,000 |
1.8 |
| COVID-19 |
2019 |
2020 |
11,400 |
11,400 |
0.1 |
| Year |
Malaria |
Cholera |
Measles |
Tuberculosis |
Meningitis |
HIV/AIDS |
COVID-19 |
| 1990 |
672,518 |
2,487 |
670,000 |
|
1,903 |
310,000 |
|
| 1991 |
692,990 |
19,302 |
550,000 |
|
1,777 |
360,000 |
|
| 1992 |
711,535 |
8,214 |
700,000 |
|
2,482 |
440,000 |
|
| 1993 |
729,735 |
6,761 |
540,000 |
|
1,986 |
540,000 |
|
| 1994 |
743,143 |
10,750 |
540,000 |
|
3,335 |
620,000 |
|
| 1995 |
761,617 |
5,045 |
400,000 |
|
4,787 |
720,000 |
|
| 1996 |
777,012 |
6,418 |
510,000 |
|
3,325 |
870,000 |
|
| 1997 |
797,091 |
6,371 |
420,000 |
|
5,254 |
1,060,000 |
|
| 1998 |
816,733 |
10,832 |
560,000 |
|
4,929 |
1,210,000 |
|
| 1999 |
834,692 |
9,221 |
550,000 |
|
2,705 |
1,390,000 |
|
| 2000 |
851,785 |
5,269 |
555,000 |
1,700,000 |
4,298 |
1,540,000 |
|
| 2001 |
885,057 |
2,897 |
550,000 |
1,680,000 |
6,398 |
1,680,000 |
|
| 2002 |
911,230 |
4,564 |
415,000 |
1,710,000 |
6,122 |
1,820,000 |
|
| 2003 |
934,048 |
1,894 |
490,000 |
1,670,000 |
7,441 |
1,965,000 |
|
| 2004 |
934,544 |
2,345 |
370,000 |
1,610,000 |
6,428 |
2,003,000 |
|
| 2005 |
927,109 |
2,272 |
375,000 |
1,590,000 |
6,671 |
2,000,000 |
|
| 2006 |
909,899 |
6,300 |
240,000 |
1,550,000 |
4,720 |
1,880,000 |
|
| 2007 |
895,528 |
4,033 |
170,000 |
1,520,000 |
7,028 |
1,740,000 |
|
| 2008 |
874,087 |
5,143 |
180,000 |
1,480,000 |
4,363 |
1,630,000 |
|
| 2009 |
831,483 |
4,946 |
190,000 |
1,450,000 |
3,187 |
1,530,000 |
|
| 2010 |
788,442 |
7,543 |
170,000 |
1,420,000 |
2,198 |
1,460,000 |
|
| 2011 |
755,544 |
7,781 |
200,000 |
1,400,000 |
3,726 |
1,400,000 |
|
| 2012 |
725,676 |
3,034 |
150,000 |
1,370,000 |
3,926 |
1,340,000 |
|
| 2013 |
710,114 |
2,102 |
160,000 |
1,350,000 |
3,453 |
1,290,000 |
|
| 2014 |
695,005 |
2,231 |
120,000 |
1,340,000 |
2,992 |
1,240,000 |
|
| 2015 |
662,164 |
1,304 |
150,000 |
1,310,000 |
|
1,190,000 |
|
| 2016 |
625,883 |
2,420 |
90,000 |
1,290,000 |
|
1,170,000 |
|
| 2017 |
619,825 |
|
100,000 |
1,270,000 |
|
1,150,000 |
|
| 2018 |
|
|
|
1,240,000 |
|
|
|
| 2019 |
|
|
|
|
|
|
|
| 2020 |
|
|
|
|
|
|
16,514 |
