I disagree often with the many details that underlie the arguments of Thomas Piketty and Emmanuel Saez. That being said, I am also a great fan of their work and of them in general. In fact, I think that both have made contributions to economics that I am envious to equal. To be fair, their U-curve of inequality is pretty much a well-confirmed fact by now: everyone agrees that the period from 1890-1929 was a high-point of inequality which leveled off until the 1970s and then picked up again.
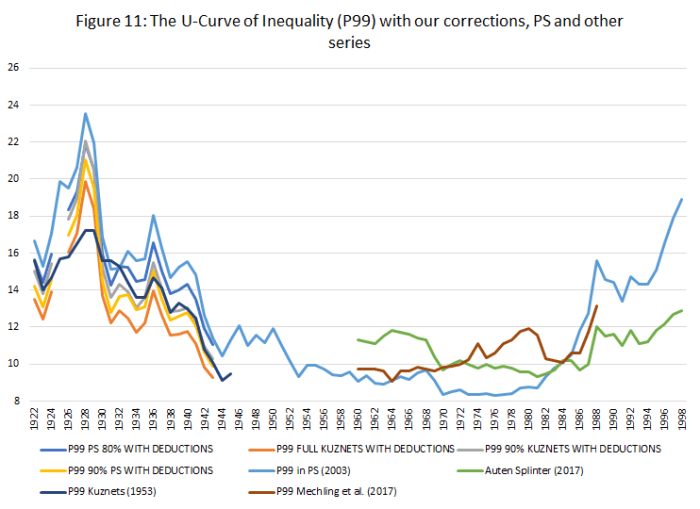
Nevertheless, while I am convinced of the curvilinear aspect of the evolution of income inequality in the United State as depicted by Piketty and Saez, I am not convinced by the amplitudes. In their 2003 article, the U-curve of inequality really looks like a “U” (see image below). Since that article, many scholars have investigated the extent of the increase in inequality post-1980 (circa). Many have attenuated the increase, but they still find an increase (see here here here here here here here here here). The problem is that everyone has been considering the increase – i.e. the right side of the U-curve. Little attention has been devoted to the left side of the U-curve even though that is where data problems should be considered more carefully for the generation of a stylized fact. This is the contribution I have been coordinating and working on for the last few months alongside John Moore, Phil Magness and Phil Schlosser.
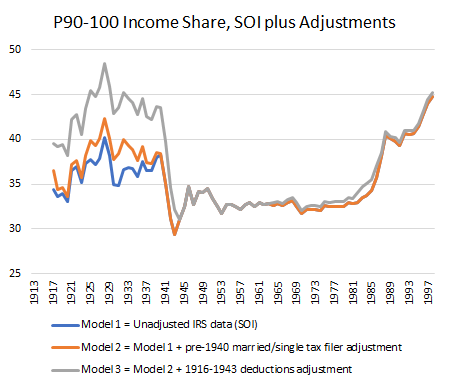
To arrive at their proposed series of inequality, Piketty and Saez used the IRS Statistics of Income (SOI) to derive top income fractiles. However, the IRS SOI have many problems. The first is that between 1917 and 1943, there are many years where there are less than 10% of the potential tax population that files a tax return. This prohibits the use of a top 10% income share in many years unless an adjustment is made. The second is that prior to 1943, the IRS reports net income and reports adjusted gross income after 1943. As such, to link post-1943 with pre-1943, there needs to be an additional adjustment. Piketty and Saez made some seemingly reasonable assumptions, but they have never been put to the test regarding sensitivity and robustness. This is leaving aside issues of data quality (I am not convinced IRS data is very good as most of it was self-reported pre-1943 which is a period with wildly varying tax rates). The question here is “how good” are the assumptions?
What we did is verify each assumption to see their validity. The first one we tackle is the adjustment for the low number of returns. To make their adjustments, Piketty and Saez used the fact that single households and married households filed in different quantities relative to their total population. Their idea is that a year in which there was a large number of return was used, the ratio of single to married could be used to adjust the series. The year they used is 1942. This is problematic as 1942 is a war year with self-reporting when large quantities of young American males are abroad fighting. Using 1941, the last US peace year, instead shows dramatically different ratios. Using these ratios knocks off a few points from the top 10% income share. Why did they use 1942? Their argument was there was simply not enough data to make the correction in 1941. They point to a special tabulation in the 1941 IRS-SOI of 112,472 1040A forms from six states which was not deemed sufficient to make to make the corrections. However, later in the same document, there is a larger and sufficient sample of 516,000 returns from all 64 IRS collection districts (roughly 5% of all forms). By comparison, the 1942 sample Piketty and Saez used to correct only had 455,000 returns. Given the war year and the sample size, we believe that 1941 is a better year to make the adjustment.
Second, we also questioned the smoothing method to link net income-based series with adjusted-gross income based series (i.e. pre-1943 and post-1943 series). The reason for this is that the implied adjustment for deductions made by Piketty and Saez is actually larger than all the deductions claimed that were eligible under the definition of Adjusted Gross Income – which is a sign of overshot on their parts. Using the limited data available for deductions by income groups and making some assumptions (very conservative ones) to move further back in time, we found that adjusting for “actual deductions” yields a lower level of inequality. This is contrasted with the fixed multipliers which Piketty and Saez used pre-1943.
Third, we question their justification for not using the Kuznets income denominator. They argued that Kuznets’ series yielded an implausible figure because, in 1948, its use yielded a greater income for non-fillers than for fillers. However, this is not true of all years. In fact, it is only true after 1943. Before 1943, the income of non-fillers is equal in proportion to the one they use post-1944 to impute the income of non-fillers. This is largely the result of an accounting error definition. Incomes before 1943 were reported as net income and as gross incomes after that point. This is important because the stylized fact of a pronounced U-curve is heavily sensitive to the assumption made regarding the denominator.
These three adjustments are pretty important in terms of overall results (see image below). The pale blue line is that of Piketty of Saez as depicted in their 2003 paper in the Quarterly Journal of Economics. The other blue line just below it is the effect of deductions only (the adjustment for missing returns affects only the top 10% income share). All the other lines that mirror these two just below (with the exception of the darkest blue line which is the original Kuznets inequality estimates) compound our corrections with three potential corrections for the denominators. The U-curve still exists, but it is not as pronounced. When you look with the adjustments made by Mechling et al. (2017) and Auten and Splinter (2017) for the post-1960 period (green and red lines) and link them with ours, you can still see the curvilinear shape but it looks more like a “tea saucer” than a pronounced U-curve.
In a way, I see this as a simultaneous complement to the work of Richard Sutch and to the work of Piketty and Saez: the U-curve still exists, but the timing and pattern is slightly more representative of history. This was a long paper to write (and it is a dry read given the amount of methodological discussions), but it was worth it in order to improve upon the state of our knowledge.